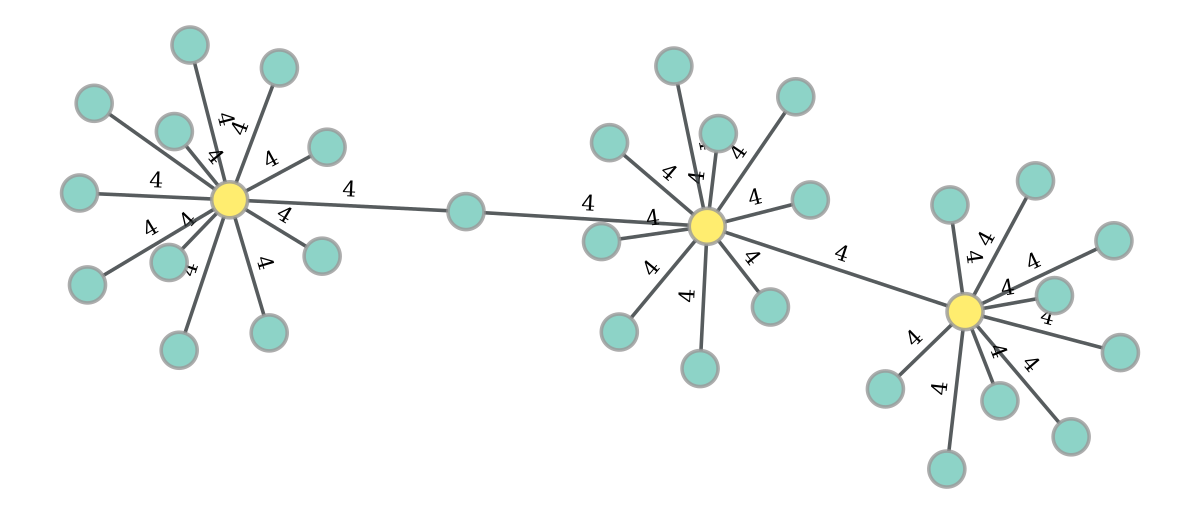
we noticed that with certain weighted graphs minimize_blockmodel_dl() tends to put hubs (vertices with many edges) into the same cluster. Please find a minimal example below, which produces the clustered graph in the attached plot. This happens even if edge weights are distributed uniformly over edges. Is this intended behavior?
We wonder if a possible explanation could be that the WSBM is fit to predict edge weights *as well as edge probabilities*. (Compare to formulas (1) and (4) in [1].) Hence, vertices with similar degrees tend to end up in the same cluster, if the edge weights do not contradict this. Is this correct?
In case the above makes any sense, is there a way to suppress the likelihood of the edge probabilities as in [2] where the alpha-parameter can be used to fit "only to the weight information"? (Compare to formula (4) in [2].)
This is also related to the question we asked here:
[1] Tiago Peixoto. 2017. Nonparametric weighted stochastic block models. Physical Review E, 97.
[2] C. Aicher, A. Z. Jacobs, and A. Clauset. 2014. Learning latent block structure in weighted networks. Journal of Complex Networks, 3(2):221–248.
This has nothing to do with having weights or not; if you use an
unweighted SBM you get the same behavior.
This clustering makes sense under the model, because a random multigraph
model with the same degree sequence would yield a larger number of
connections between the hubs, and between the nodes with smaller degree.
we noticed that with certain weighted graphs minimize_blockmodel_dl() tends to put hubs (vertices with many edges) into the same cluster. Please find a minimal example below, which produces the clustered graph in the attached plot. This happens even if edge weights are distributed uniformly over edges. Is this intended behavior?
We wonder if a possible explanation could be that the WSBM is fit to predict edge weights *as well as edge probabilities*. (Compare to formulas (1) and (4) in [1].) Hence, vertices with similar degrees tend to end up in the same cluster, if the edge weights do not contradict this. Is this correct?
This has nothing to do with having weights or not; if you use an
unweighted SBM you get the same behavior.
I see that we are probably mixing up two things here. Regarding this point:
is there a way to suppress the likelihood of the edge probabilities as in [2] where the alpha-parameter can be used to fit "only to the weight information"? (Compare to formula (4) in [2].)
[...]
[2] C. Aicher, A. Z. Jacobs, and A. Clauset. 2014. Learning latent block structure in weighted networks. Journal of Complex Networks, 3(2):221–248.
How does the graph-tools implementation relate to the alpha-parameter in formula (4)? Is it equivalent to giving equal weight to edge probabilities and weights (alpha = 0.5)?
This clustering makes sense under the model, because a random multigraph
model with the same degree sequence would yield a larger number of
connections between the hubs, and between the nodes with smaller degree.
is there a way to suppress the likelihood of the edge probabilities as in [2] where the alpha-parameter can be used to fit "only to the weight information"? (Compare to formula (4) in [2].)
[...]
[2] C. Aicher, A. Z. Jacobs, and A. Clauset. 2014. Learning latent block structure in weighted networks. Journal of Complex Networks, 3(2):221–248.
How does the graph-tools implementation relate to the alpha-parameter in formula (4)? Is it equivalent to giving equal weight to edge probabilities and weights (alpha = 0.5)?
This parameter is not implemented in graph-tool.
Note that such a parameter does not have an obvious interpretation from
a generative modelling point of view, specially in a Bayesian way. We
cannot just introduce ad-hoc parameters to cancel certain parts of the
likelihood, without paying proper attention to issues of normalization,
etc, and expect things to behave consistently.
In other words, I do not fully agree with the alpha parameter of Aicher
et al.
Is it possible to use LatentMultigraphBlockState() with a weighted graph?
is there a way to suppress the likelihood of the edge probabilities as in [2] where the alpha-parameter can be used to fit "only to the weight information"? (Compare to formula (4) in [2].)
[...]
[2] C. Aicher, A. Z. Jacobs, and A. Clauset. 2014. Learning latent block structure in weighted networks. Journal of Complex Networks, 3(2):221–248.
How does the graph-tools implementation relate to the alpha-parameter in formula (4)? Is it equivalent to giving equal weight to edge probabilities and weights (alpha = 0.5)?
This parameter is not implemented in graph-tool.
Note that such a parameter does not have an obvious interpretation from
a generative modelling point of view, specially in a Bayesian way. We
cannot just introduce ad-hoc parameters to cancel certain parts of the
likelihood, without paying proper attention to issues of normalization,
etc, and expect things to behave consistently.
In other words, I do not fully agree with the alpha parameter of Aicher
et al.
Thanks for clarifying this. Last question: Does your doubt also concern the special case where alpha = 0, i.e., ignoring edge probabilities completely? (This is the actually interesting case for us. We are not interested in tuning this parameter in any way.)
Is it possible to use LatentMultigraphBlockState() with a weighted graph?
Not yet.
We will open a feature request then, in case there is none yet.
concern the special case where alpha = 0, i.e., ignoring edge
probabilities completely? (This is the actually interesting case for
us. We are not interested in tuning this parameter in any way.)
I'd have to look at this more closely, but I think this is strange since
the edges define the support of the distribution. The more correct thing
to do, in my opinion, would be to marginalize over the edges. This might
end up being equivalent o setting alpha=0, but I would need to check.
concern the special case where alpha = 0, i.e., ignoring edge
probabilities completely? (This is the actually interesting case for
us. We are not interested in tuning this parameter in any way.)
I'd have to look at this more closely, but I think this is strange since
the edges define the support of the distribution. The more correct thing
to do, in my opinion, would be to marginalize over the edges. This might
end up being equivalent o setting alpha=0, but I would need to check.
You're probably quite busy, but as we would really profit from this, I would then open a feature request, if you don't stop me right now.